

Panther Users: Set up Desktop Monitoring Screen
Panther users can execute the following 10 steps to set up a monitoring screen on their desktop that will give them an excellent picture of what is happening in Millennium from a messaging perspective:
- From the Panther Domain Explorer (left-hand side of the application screen), verify that the domain – e.g., prod – is expanded so that you can see all of the nodes in prod.
- Expand each node so you can see the Monitors, one of which should be the Shared Service Queue Depths Monitor.
- In the Domain Explorer, select Desktop, the topmost item of Domain Explorer.
- In the Panther5 Menu (top bar of the screen), select Tools, then Desktop and then New Desktop.
- Highlight four squares to make a 2×2 grid.
- Provide a Desktop Name – I recommend calling it Performance – and then select OK. You should now see the Domain Explorer on the left of the screen and four boxes to the right.
- From Domain Explorer, left-click and drag node1’s Shared Service Queue Depth into the top left-hand blank square, node2’s Shared Service Queue Depth into the top right-hand square, Queues into the bottom left-hand square and Interfaces into the bottom right-hand square.
- In the top Shared Service Queue Depth panes, you need to left-click twice on the Maximum column. This will sort the output so any shared service queuing since you started the monitor will show at the top of the list.
- In the Queues pane, you want to verify you can see the Depth column with a downward pointing triangle. This makes certain any MQ queues that are backing up show at the top of the list.
- In the Interfaces pane, move the Depth column next to the Description column and click on Depth twice so the triangle points down. This will show you what interfaces are backed up.
So what does all this tell you? You want to watch for any Maximum and Depth columns that sustain values over 1. Typically, if the proprietary middleware is not keeping up, you will have one or two Shared Service Queues that are backing up (e.g., cpmscript005, which is a service name, not the name of the server in the Servers display, which would be CPM Script005). The MQ queue names follow a similar pattern: If the Depth column is building or not going to 0, then you have to take the queue name (e.g, CERN.CPMPROCESS) and translate this in the Servers display (CPM Process). The Interfaces Description has an OP_ prefix on it in the Servers display. Exceptions include OEN.Routerand OEN.Controller, where these would be named OEN Router and OEN Controller.
Issues in Interfaces are trickier to address, and we will cover what to do with interfaces queuing in a later blog.
Begin Treatment
The quickest first treatment once you have determined which nodes are not keeping up is to add more instances (application executables) of the application servers on these nodes. If this addition makes the Maximum in Shared Service Queue Depths or the Depth on Queues go away, then you simply have to change the instance value of that server in either the Servers or Configuration control.
To add more instances of a server dynamically, select the node that is backing up in Domain Explorer and select Servers. Sort the display by Entry ID so the triangle is pointed up. Right-click anywhere in the Server display and select Preferences and then the Filter tab. Check the Use server state filter as well as the following Visible server states during a filter
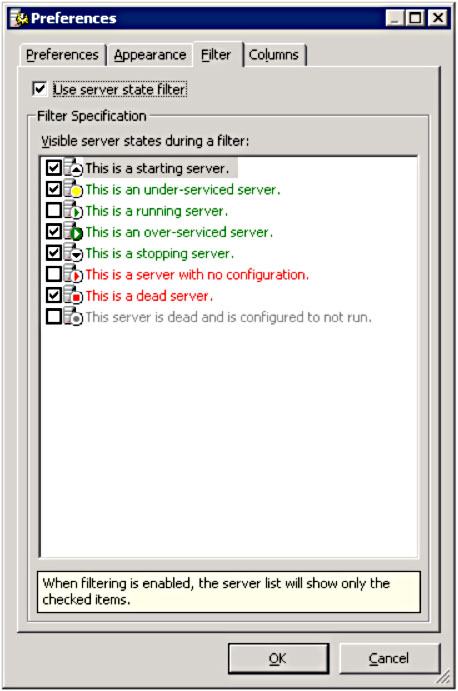
Then select OK.
Right-click on the server Description or server Entry ID of the SCP Entry that is queuing. Select Start Instance. Once the new server is in a running state, verify if it alleviated the queuing backlog and, if it didn’t, continue the process up to five new instances. If the addition of instances reduces the queuing, right-click on the server and change the number in Instances to match the number needed to keep up with the workload. Make this same change on any other application nodes that are overloaded and start the additional servers.
If adding instances does not clear the queue, you should stop and evaluate what other factors may be causing this bottleneck. You will need to determine the Shared Service Proxy (SSP) that the instances are attached to and then create a dedicated SSP for this service. This procedure will be covered next week.
Without Panther: Use Millennium Point Tools
If you do not have Panther, you will want to use Millennium point tools, such as mon_ss and sysmon, and perform the following:
- If you start mon_ss either on the node running Millennium applications or on the Citrix server or fat client with Millennium installed on it, use the following switches: mon_ss <node name=””> -sort max -interval 7</node>
- Enter your username, domain name and password. Let this run.
- Repeat these steps in separate telnet/ssh or dos windows until you have all of the application nodes running one instance of this.
- Each of these windows will have to be resized to fit in the screen.
So what are you looking for? Watch for the Max (maximum queue depth) column to be greater than 2. A reading of less than 2 is usually normal and often indicates a sampling issue. You do need to be concerned, however, if there is a sustained Max, meaning there are # symbols growing from left to right of the service name. This typically means one of two things: 1) You do not have enough of the application servers (executables) running or 2) the Cerner middleware server you are attached to is not able to keep up with the workload. Less often it means that you have database issues either with space, locks or Oracle instances failing.
Issues in Interfaces are trickier to address, and we will cover what to do with interfaces queuing in a later blog.
Begin Treatment
The quickest first treatment is to add more instances (application executables) of the application servers on any node that is not keeping up. Add one at a time, up to a maximum of five. If this addition makes the # symbols go away, then you just have to change the instance value of the SCP Entry to match the number needed to keep up with the workload. Make this same change on any other application nodes that are overloaded and start the additional servers.
If adding instances does not clear the queue, you should stop and evaluate what other factors may be causing this bottleneck. You will need to determine the Shared Service Proxy (SSP) that the instances are attached to and then create a dedicated SSP for this service. This procedure will be covered next week.