

Last week we discussed the importance of analyzing scripts and how to execute CCL commands to gather snapshots and produce an analysis file. This week we’re going to talk about what is and isn’t important in the analysis file, and what to look at to determine which scripts are causing performance issues on your system. Specifically, we are going to help you identify scripts that have a high impact each time they run.
As you may recall, the CCL command to create a snapshot is:
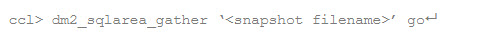
and the CCL command to create an analysis of the two snapshots is:
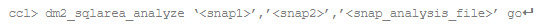
When you open the analysis file in Excel (remember to use a .CSV extension when specifying file names), you may be overwhelmed by the amount of information that is presented. So your first step is to identify which columns are important for analysis and what those columns represent. They are:
- SCRIPT_OBJECT
Script that contains the SQL statement that was executed. - TYPE
Column contains either the word TOTAL or the word DETAIL. For analysis purposes we are only interested in the DETAIL records, so we will filter out the TOTAL rows. - SCORE
Calculation based on the following formula: SCORE = BUFFER_GETS + (200 x DISK_READS) + (200 x EXECUTIONS). While the ranking this produces is debatable, the intent is to produce an overall view of system impact, rather than the impact of individual statistics. - BUFFER_GETS
Total number of memory reads that the SQL command performed. - DISK_READS
Number of disk reads that the statement made. - EXECUTIONS
Number of times the statement was executed. - CPU_TIME
Total amount of CPU time used by the statement. - SQL
SQL statement.
Now, to identify scripts that have a high impact each time they run, you must consider all of the metrics that give indications of script performance – not just CPU_TIME or SCORE. What we are looking for are SQL statements that have a high impact (whether that is measured in CPU_TIME, DISK_READS, or BUFFER_GETS) along with a low number of executions. To identify these scripts, follow these steps:
- Insert a column after the SCORE column and enter Cost_Per_Executioninto the first row of this new column.
- In the second row of the Cost_Per_Execution column, enter the formula to match this equation: (BUFFER_GETS * DISK_READS+ BUFFER_GETS * CPU_TIME + DISK_READS * CPU_TIME)/EXECUTIONS
Your equation will look similar to this: =(I2 * J2 + I2 * P2 + J2 * P2)/L2
Note: Change 0 in Executions to 0.01 or delete (prevents division by zero), and delete rows with “N/A” for CPU_TIME.
If at your site you feel that one of the metrics is more costly, you can modify the equation to reflect that. - Copy this equation to every other row in this column where there is corresponding analysis data.
- Filter the data in the spreadsheet. In Excel 2007, go to the Data ribbon and click the Filter button. After you have turned on the filter feature, you should see a button with a down arrow in the first row of every column.
- Click the down arrow in the TYPE column, uncheck TOTAL, and then click OK.
- Click the down arrow in the Cost_Per_Execution column, and then click Sort Largest to Smallest.
You should now have a spreadsheet where the scripts with the highest impact are at the top. If you have any questions about the Cost_Per_Execution equation, post a comment at the end of the blog.
So what do you do now that you’ve identified a script that has a high impact every time it is run? The answer is, it depends upon why the score is high: Does it have a high number of BUFFER_GETS, DISK_READS, CPU_TIME, or some combination of these? Here is a starting point based on the metric causing the high score:
- A high number of BUFFER_GETS is an indication that the script has to sift through a large number of rows (for example, joining to a table on an un-indexed column). To address this, you could either create appropriate indexes or have the script modified to take advantages of existing indexes. This could also indicate the table has historical data, and purges could reduce the impact of the script.
- A high number of DISK_READS is an indication that the data requested by the script is not in the Oracle SGA, which can be resolved in various ways, including (but not limited to) pinning the table in the SGA and/or increasing your SGA size. This solution does not take into account the system resources at your site; discussing options with your Oracle DBA and system administrator is recommended.
- A high CPU_TIME is an indication that Oracle has to process a large amount of data. To identify this in a script, check for functions within the script – for example, “WHERE (END_DT_TM – BEG_DT_TM) > :1”. Functions cause Oracle to perform full table scans and use the CPU to calculate the results of the functions. To address this, evaluate whether the script’s conditions are necessary and as efficient as possible, or if the script can be modified to not include functions within the script.
Once appropriate indexes are in place, the SGA is sized appropriately, and the scripts are as efficient as possible, scheduling them at appropriate times or modifying end-user workflows can alleviate negative end-user impact.
Prognosis: Data analysis can identify and address scripts that have a high impact every time they are run.
Next week: Analyzing scripts that create a high impact due to the number of times they run.