

Last week our series on Millennium® performance issues for RHOs (remote-hosted organizations) walked you through the necessary steps for evaluating if you are queuing in WebsphereMQ. This week we will cover another area where queuing can be a problem—in Millennium’s proprietary middleware. Called Shared Services, Shared Service Proxies (SSPs), or Shared Service Controllers, depending on your Millennium version, they provide the throughput for transactions your clinicians and office staff rely on to deliver quality patient care.
We need to answer the same questions we addressed last week: What is it, and why do I care?
Shared services are used for synchronous client requests, which means that time is of the essence — while a request is waiting to be processed, a user is waiting with an hourglass. If a message is lost, it is generally assumed the process or executable making the request (the client application) will either time out (retry or give up) or provide a status indicating that a manual retry has to happen.
Shared services are the way Millennium handles scaling up to meet the demands of large clients. Shared services allow you to simply increment the number of server instances to meet the demands of the system. Because the client application is not directly connected to the application server, starting another instance of the server will have immediate benefit for all applications using that service. Figure 1 shows a simple overview of what is happening.
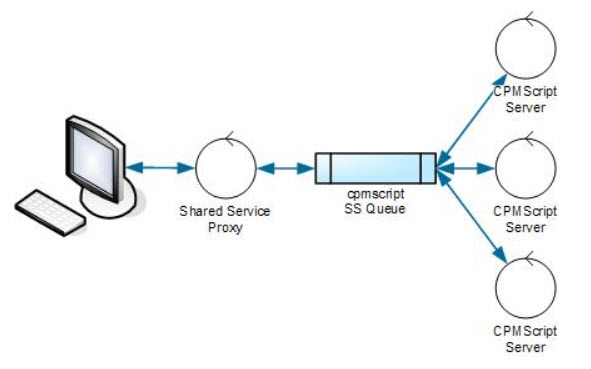
Figure 1—Starting at the left of Figure 1, we have a client application that is connected to an SSP, a server that handles almost all client application requests. Each SSP manages one or more shared service queues (SSQs), which is how the shared service servers get their messages. In the figure, three CPM Script servers are processing data from the cpmscript SSQ. Because an SSP can manage multiple SSQs, increasing the number of SSPs can reduce the number of queues each proxy has to manage, which can achieve a higher throughput and more consistent response times.
Recently, Cerner introduced the use of IBM MQ to replace the SSP for shared services. The architecture of this solution is a little different but still has to be monitored for backlogs. Figure 2 gives a simple overview of how shared services work with IBM MQ.
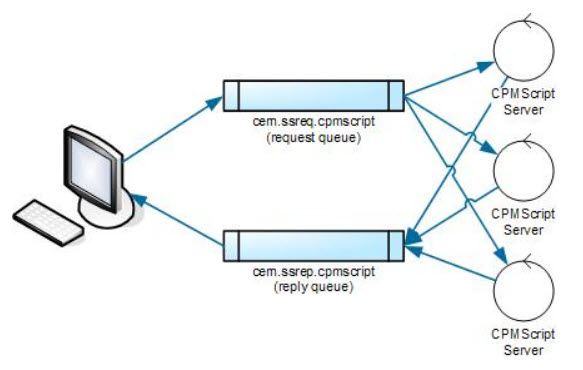
Figure 2—Starting at the left of Figure 2, we have a client application that is connected to both a request and a reply queue. These queues are used to transport the client request to the application servers and the reply back to the client application.
As I emphasized last week, it’s important to know if you are queuing—or backing up—because queuing means that a clinician or someone using Millennium is being forced to wait. And a wait can translate into a delay in care delivery or business transactions.
So how do I find out if I’m having a queuing issue with my SSQs?
If you have Softek Panther, you can use the Shared Service Queue Monitor. Without Panther, any Citrix or fat client should have the Millennium utility called mon_ss.exe. For an explanation of how to use these utilities, click here. If you are using IBM MQ for your shared service queuing mechanism, you can refer to last week’s blog, “MQ’s Path for Rapid Transactions.”
What do I do if I’m having queuing issues?
If you discover SSP backlog issues, you typically can improve transaction throughput by adding more server instances to your Application nodes (assuming you have enough generic SSPs) or creating a dedicated SSP for the busy services and moving the server workload to these new SSPs (refer to our post on configuring a dedicated SSP). You should have around 24 generic SSPs on each Application node for optimal throughput.
Prognosis: Adding more server instances or creating dedicated SSPs will alleviate backlog issues with your SSPs and stabilize Millennium’s performance.
Next week: Messaging throughput analysis for Millennium’s FSI/ESO servers (interfaces).